Abstract
Method
ERASE fuses visual and UWB localization information. By projecting the UWB position estimates from physical coordinates to pixel coordinates, the system estimates the number of people in the camera view and initializes tentative bounding box solutions (blue in the figure below), thereby accelerating and improving the accuracy of vision-based human detection. The system then optimizes these bounding boxes (red is the final prediction). The system finally redacts the regions containing privacy information.
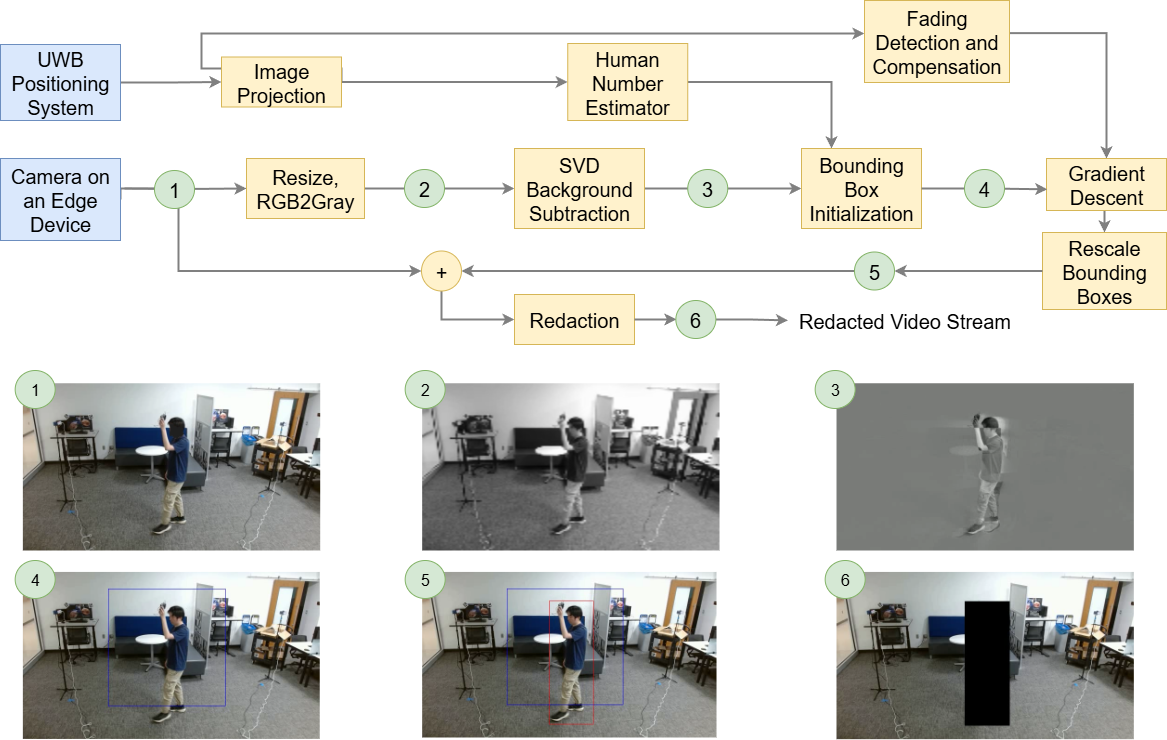
Figure 1: ERASE system flow chart. Sub-figures 1 - 6 show the intermediate outputs at each stage of ERASE, illustrating the redaction process. The red box is the final bounding box prediction.
Visuals & Key Results
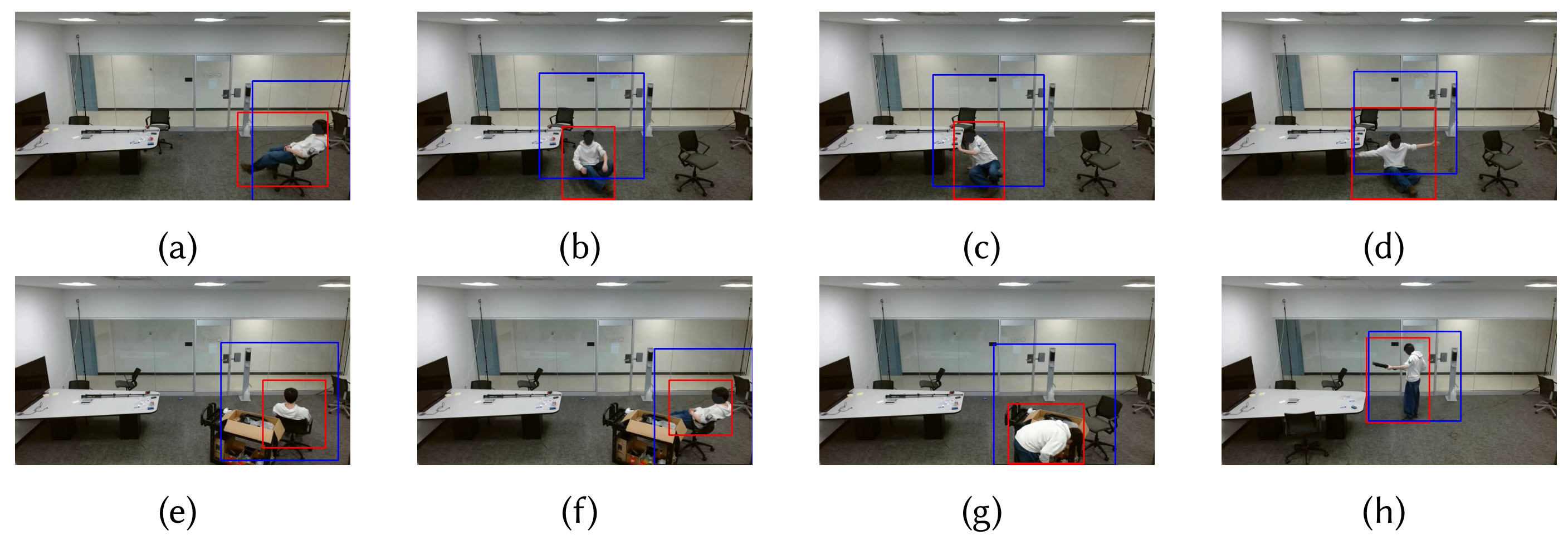
Figure 2: ERASE is capable of detecting individuals across a variety of poses and under partial occlusion. The predicted bounding boxes (in red) accurately enclose the human figures in these challenging scenarios.
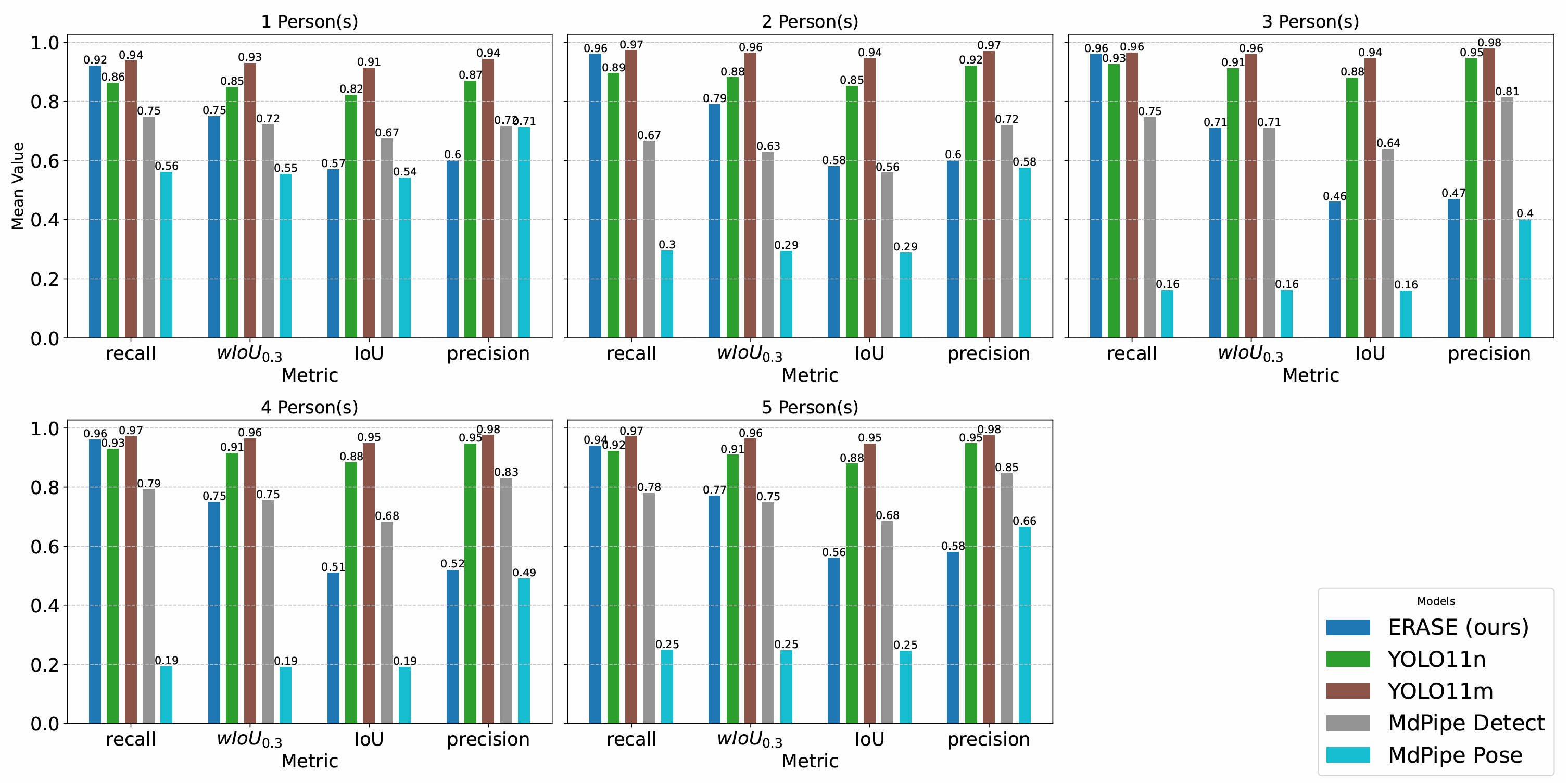
Figure 3: Accuracies as functions of redaction method and number of people in scenes. YOLO11m achieves the best accuracy in all measures. ERASE achieves good results in recall and wIoU0.3, which implies that it is able to redact most privacy-relevant pixels without redacting many privacy-irrelevant pixels. However, it has lower precision compared to the neural network models, implying that its estimated boxes cover more privacy-irrelevant pixels. ERASE is the only one capable of running in real-time.
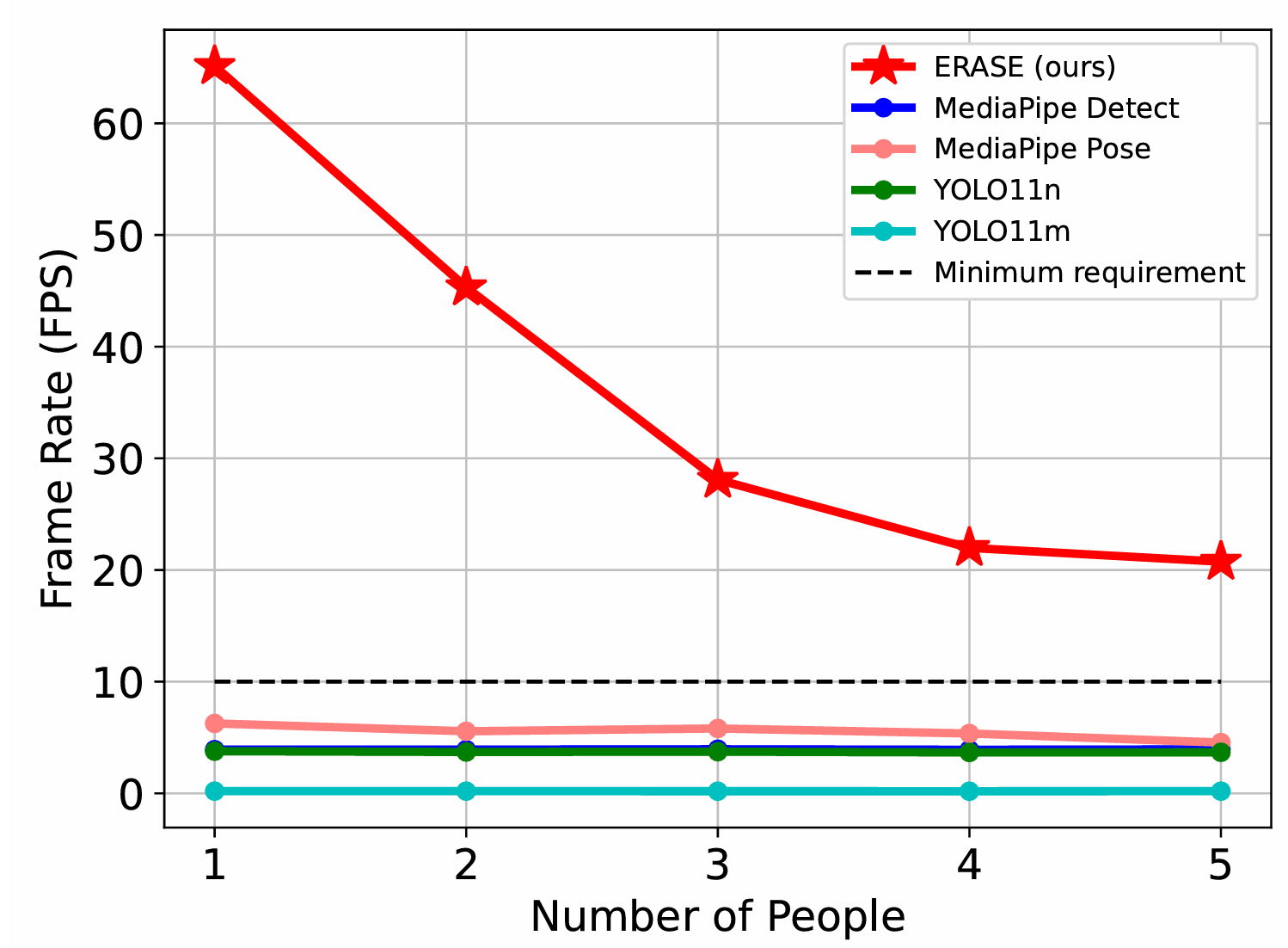
Figure 4: Note that the lines for YOLO11n and MediaPipe Detect overlap. ERASE is able to run at over 20 FPS, approximately 4X faster than the neural network models, when five people are in the scene.
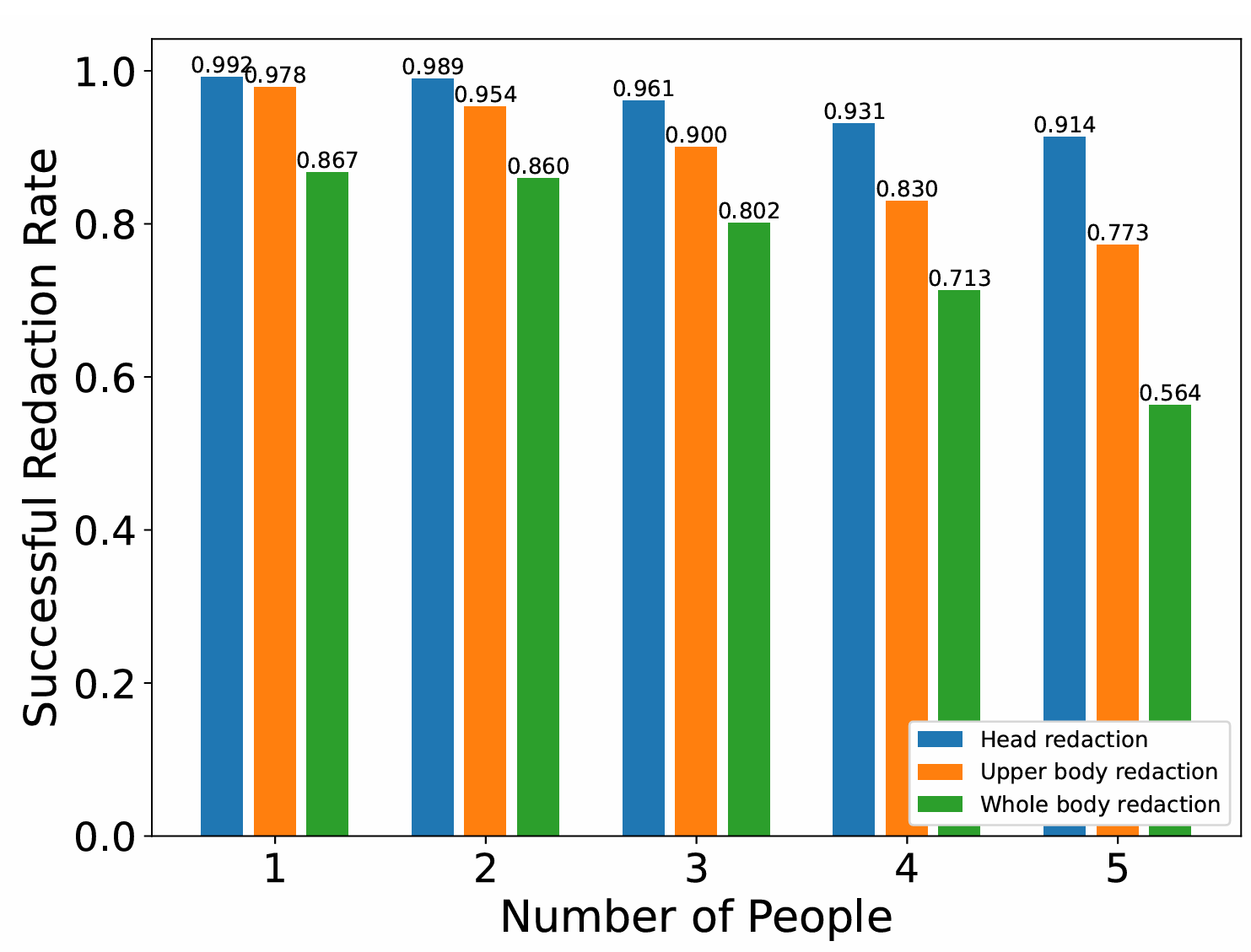
Figure 5: Success rates for redacting heads, upper bodies, and whole bodies for various numbers of people in the field of view. After redaction by ERASE, most privacy-relevant pixels are successfully removed.
Dataset and Docker Image
The data provided in the Github Repo is a subset of the full dataset. Public access without extra consent is limited to this subset. If you need access to the full dataset for research purpose, please contact the authors via email. Once you get the access, please store it securely on a local machine and do not distribute it.
For a quick evaluation, we also provide a Docker image containing necessary pre-built environment, the repo, and the partial dataset. The image is published on Docker Hub. To pull the image, run:
docker pull qhaotian0525/erase:v1.0
See here for how to use the redaction code (also available in the repository under `docs/redaction.md`).
Citation
If you find our work useful in your research, please consider citing:
@article{qiao2025efficient,
author = {Qiao, Haotian and Srinivas, Vidya and Dinda, Peter and Dick, Robert P.},
title = {Efficient Video Redaction at the Edge: Human Motion Tracking for Privacy Protection},
journal = {{ACM} Trans.\ Embedded Computing Systems},
year = 2025,
volume = 24,
number = {5s},
articleno = 120,
pages = 22,
url = {https://doi.org/10.1145/3762994},
month = sep
}